Integrating Amazon Glue with ClickHouse and Spark
Amazon Glue is a fully managed, serverless data integration service provided by Amazon Web Services (AWS). It simplifies the process of discovering, preparing, and transforming data for analytics, machine learning, and application development.
Installation
To integrate your Glue code with ClickHouse, you can use our official Spark connector in Glue via one of the following:
- Installing the ClickHouse Glue connector from the AWS Marketplace (recommended).
- Manually adding the Spark Connector's jars to your Glue job.
- AWS Marketplace
- Manual Installation
-
Subscribe to the Connector
To access the connector in your account, subscribe to the ClickHouse AWS Glue Connector from AWS Marketplace. -
Grant Required Permissions
Ensure your Glue job’s IAM role has the necessary permissions, as described in the minimum privileges guide. -
Activate the Connector & Create a Connection
You can activate the connector and create a connection directly by clicking this link, which opens the Glue connection creation page with key fields pre-filled. Give the connection a name, and press create (no need to provide the ClickHouse connection details at this stage). -
Use in Glue Job
In your Glue job, select theJob detailstab, and expend theAdvanced propertieswindow. Under theConnectionssection, select the connection you just created. The connector automatically injects the required JARs into the job runtime.
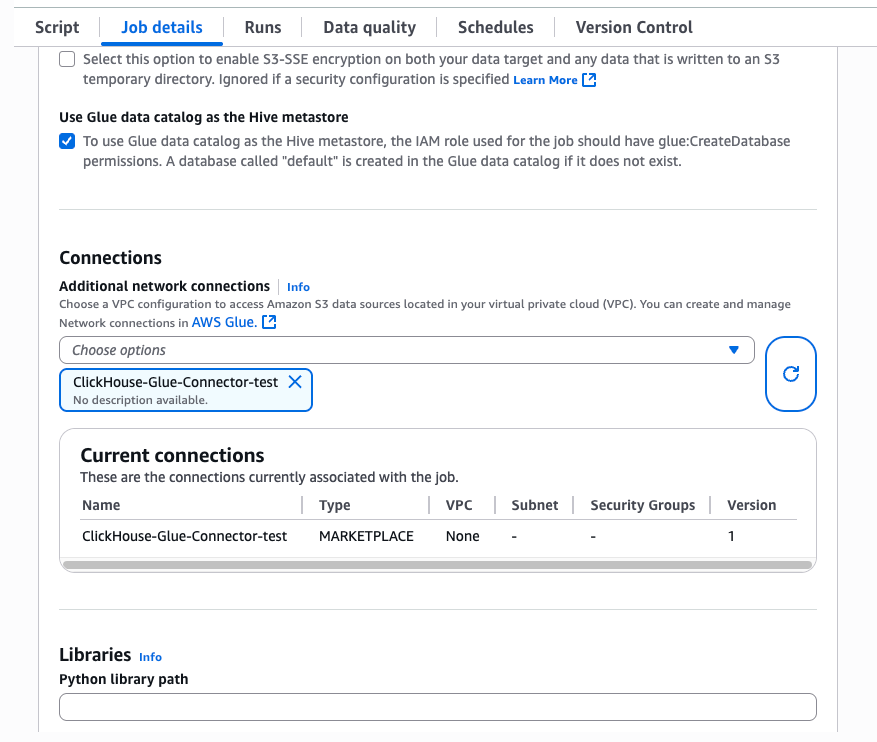
Note
The JARs used in the Glue connector are built for Spark 3.3, Scala 2, and Python 3. Make sure to select these versions when configuring your Glue job.
To add the required jars manually, please follow the following:
- Upload the following jars to an S3 bucket -
clickhouse-jdbc-0.6.X-all.jarandclickhouse-spark-runtime-3.X_2.X-0.8.X.jar. - Make sure the Glue job has access to this bucket.
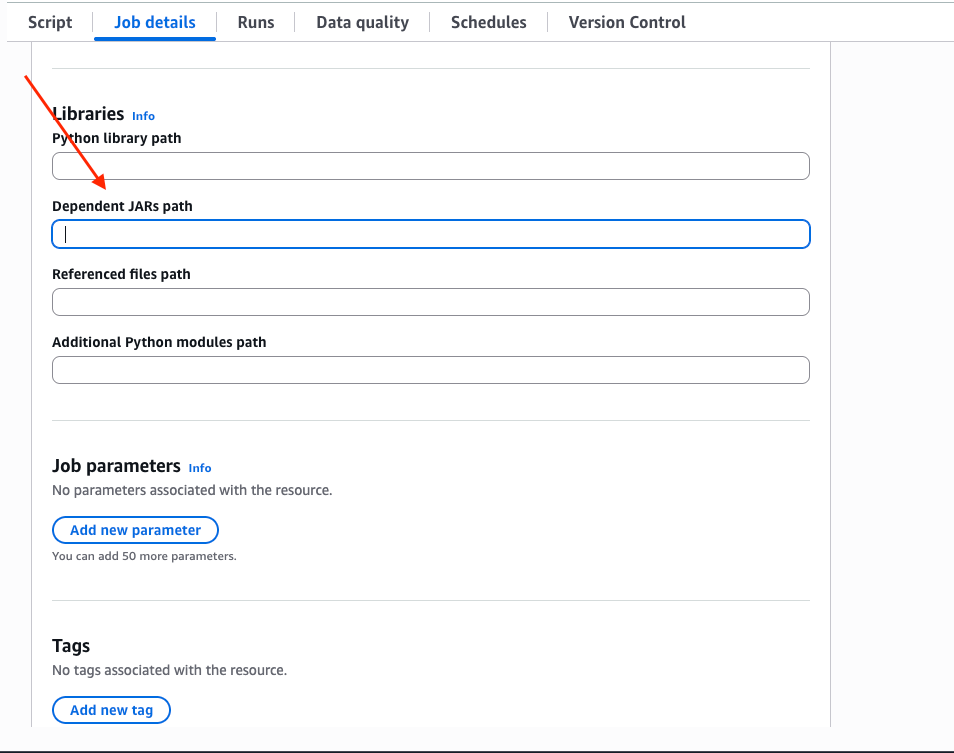
- Under the
Job detailstab, scroll down and expend theAdvanced propertiesdrop down, and fill the jars path inDependent JARs path:
Examples
- Scala
- Python
For more details, please visit our Spark documentation.
